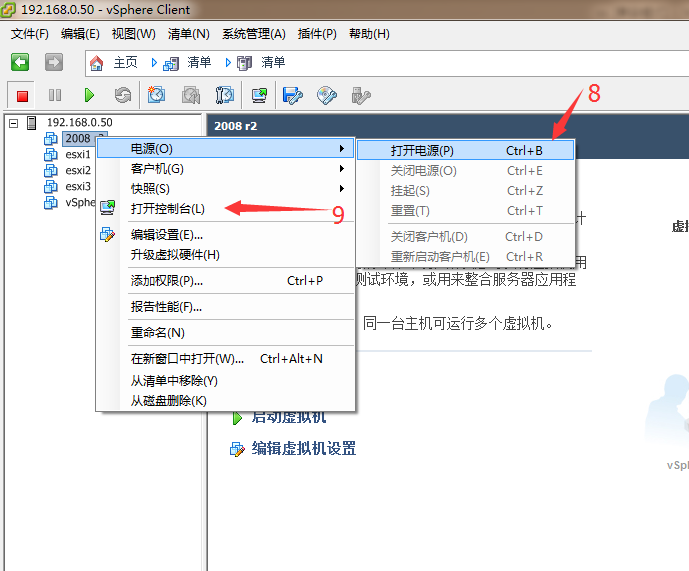
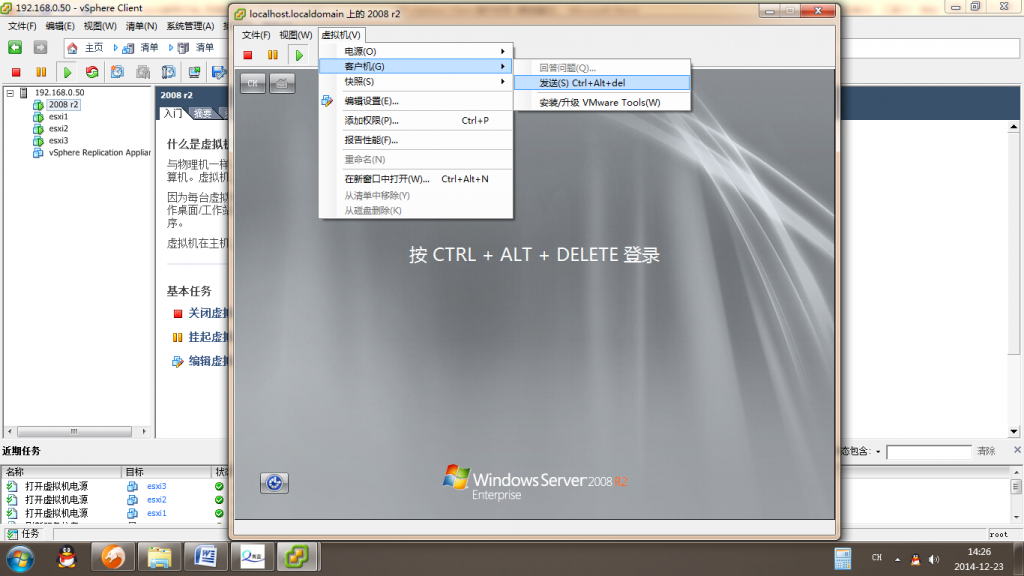
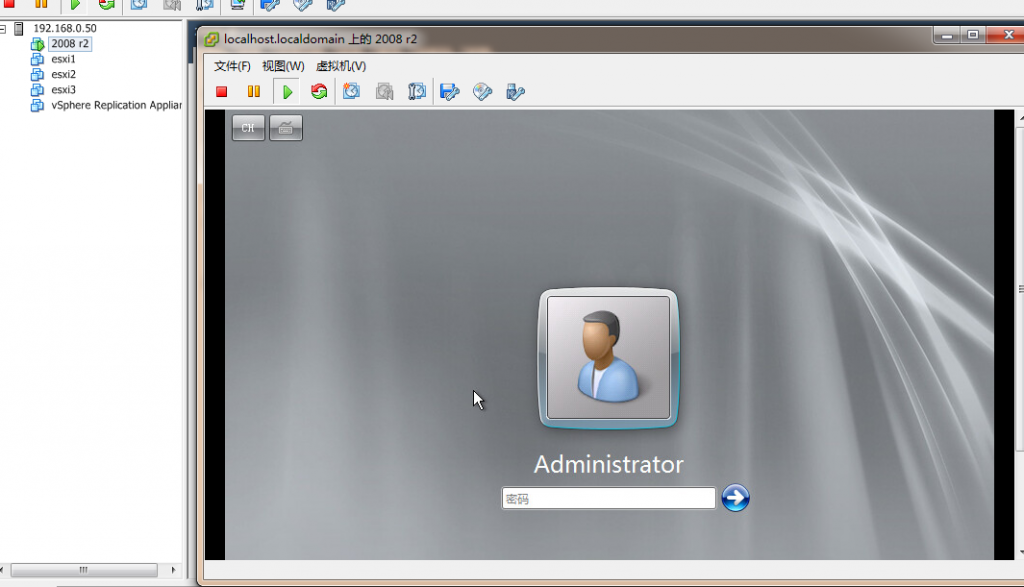
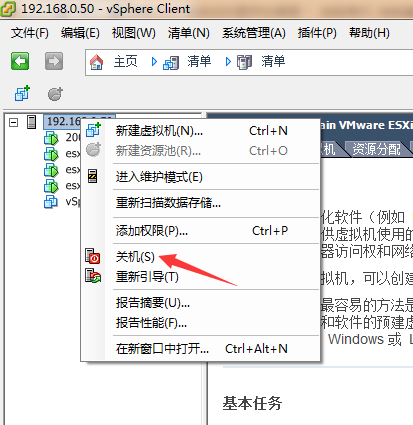
通过linux自带的bond技术实现linux双网卡绑定和负载均衡
绑定的前提条件:芯片组型号相同,而且网卡应该具备自己独立的BIOS芯片
一、建立虚拟网络接口ifcfg-bond0文件
[root@jason ~]# cd /etc/sysconfig/network-scripts/
[root@jason network-scripts]# cp ifcfg-eth0 ifcfg-bond0
其内容为:
[root@jason network-scripts]# more ifcfg-bond0
# Broadcom Corporation NetXtreme II BCM5708 Gigabit Ethernet
DEVICE=bond0
BROADCAST=10.0.0.255
IPADDR=10.0.0.3
NETMASK=255.255.255.0
NETWORK=10.0.0.0
MTU=1500
GATEWAY=10.0.0.1
[root@jason network-scripts]#
二、编辑原有网卡eth0和eth信息文件
使其内容为:
[root@jason network-scripts]# more ifcfg-eth0
# Broadcom Corporation NetXtreme II BCM5708 Gigabit Ethernet
DEVICE=eth0
BOOTPROTO=none
ONBOOT=yes
TYPE=Ethernet
MASTER=bond0
slave=yes
[root@jason network-scripts]# more ifcfg-eth1
# Broadcom Corporation NetXtreme II BCM5708 Gigabit Ethernet
DEVICE=eth1
BOOTPROTO=none
ONBOOT=yes
TYPE=Ethernet
MASTER=bond0
slave=yes
[root@jason network-scripts]#
三、编辑/etc/modprobe.conf加入下面两行
[root@jason network-scripts]# vi /etc/modprobe.conf
alias bond0 bonding
options bond0 miimon=100 mode=1
说明:miimon是用来进行链路监测的。 比如:miimon=100,那么系统每100ms监测一次链路连接状态,如果有一条线路不通就转入另一条线路;mode的值表示工作模式,他共有0,1,2,3四种模式,常用的为0,1两种。
mode=0表示load balancing (round-robin)为负载均衡方式,两块网卡都工作。
mode=1表示fault-tolerance (active-backup)提供冗余功能,工作方式是主备的工作方式,也就是说默认情况下只有一块网卡工作,另一块做备份.
bonding只能提供链路监测,即从主机到交换机的链路是否接通。如果只是交换机对外的链路down掉了,而交换机本身并没有故障,那么bonding会认为链路没有问题而继续使用
加入后我的modprobe.conf内容为:
[root@jason network-scripts]# more /etc/modprobe.conf
alias eth0 bnx2
alias eth1 bnx2
alias scsi_hostadapter aacraid
alias scsi_hostadapter1 ata_piix
alias peth0 bnx2
alias bond0 bonding
options bond0 miimon=100 mode=1
四、编辑/etc/rc.d/rc.local文件,加入
ifenslave bond0 eth0 eth1
重新启动后,负载均衡就能正常工作了,可以用ifconfig查看具体信息
[root@jason network-scripts]# ifconfig
bond0 Link encap:Ethernet HWaddr 00:1A:64:6A:55:98
inet addr:10.0.0.3 Bcast:10.0.0.255 Mask:255.255.255.0
inet6 addr: fe80::21a:64ff:fe6a:5598/64 Scope:Link
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:985369 errors:0 dropped:0 overruns:0 frame:0
TX packets:804306 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:148943796 (142.0 MiB) TX bytes:2097755332 (1.9 GiB)
eth0 Link encap:Ethernet HWaddr 00:1A:64:6A:55:98
inet6 addr: fe80::21a:64ff:fe6a:5598/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:984133 errors:0 dropped:0 overruns:0 frame:0
TX packets:804292 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:148805154 (141.9 MiB) TX bytes:2097751381 (1.9 GiB)
eth1 Link encap:Ethernet HWaddr 00:1A:64:6A:55:98
inet6 addr: fe80::21a:64ff:fe6a:5598/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:1236 errors:0 dropped:0 overruns:0 frame:0
TX packets:16 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:138642 (135.3 KiB) TX bytes:4275 (4.1 KiB)
Interrupt:16 Memory:ca000000-ca011100
通过查看bond0的工作状态查询能详细的掌握bonding的工作状态
[root@redflag bonding]# cat /proc/net/bonding/bond0
bonding.c:v2.4.1 (September 15, 2003)
Bonding Mode: load balancing (round-robin)
MII Status: up
MII Polling Interval (ms): 0
Up Delay (ms): 0
Down Delay (ms): 0
Multicast Mode: all slaves
Slave Interface: eth1
MII Status: up
Link Failure Count: 0
Permanent HW addr: 00:0e:7f:25:d9:8a
Slave Interface: eth0
MII Status: up
Link Failure Count: 0
Permanent HW addr: 00:0e:7f:25:d9:8b
以下是网上找的文档
Linux双网卡绑定实现就是使用两块网卡虚拟成为一块网卡,这个聚合起来的设备看起来是一个单独的以太网接口设备,通俗点讲就是两块网卡具有相同的IP地址而并行链接聚合成一个逻辑链路工作。其实这项 技术在Sun和Cisco中早已存在,被称为Trunking和Etherchannel技术,在Linux的2.4.x的内核中也采用这这种技术,被称为bonding。bonding技术的最早应用是在集群——beowulf上,为了提高集群节点间的数据传输而设计的。下面我们讨论一下bonding 的原理,什么是bonding需要从网卡的混杂(promisc)模式说起。我们知道,在正常情况下,网卡只接收目的硬件地址(MAC Address)是自身Mac的以太网帧,对于别的数据帧都滤掉,以减轻驱动程序的负担。但是网卡也支持另外一种被称为混杂promisc的模式,可以接收网络上所有的帧,比如说tcpdump,就是运行在这个模式下。bonding也运行在这个模式下,而且修改了驱动程序中的mac地址,将两块网卡的Mac地址改成相同,可以接收特定mac的数据帧。然后把相应的数据帧传送给bond驱动程序处理。
说了半天理论,其实配置很简单,一共四个步骤:
实验的操作系统是Redhat Linux Enterprise 3.0
绑定的前提条件:芯片组型号相同,而且网卡应该具备自己独立的BIOS芯片。
1.编辑虚拟网络接口配置文件,指定网卡IP
vi /etc/sysconfig/ network-scripts/ ifcfg-bond0
[root@redflag root]# cp /etc/sysconfig/network-scripts/ifcfg-eth0 ifcfg-bond0
2 #vi ifcfg-bond0
将第一行改成 DEVICE=bond0
# cat ifcfg-bond0
DEVICE=bond0
BOOTPROTO=static
IPADDR=172.31.0.13
NETMASK=255.255.252.0
BROADCAST=172.31.3.254
ONBOOT=yes
TYPE=Ethernet
这里要主意,不要指定单个网卡的IP 地址、子网掩码或网卡 ID。将上述信息指定到虚拟适配器(bonding)中即可。
[root@redflag network-scripts]# cat ifcfg-eth0
DEVICE=eth0
USERCTL=no
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
[root@redflag network-scripts]# cat ifcfg-eth1
DEVICE=eth1
USERCTL=no
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
3 # vi /etc/modules.conf
编辑 /etc/modules.conf 文件,加入如下一行内容,以使系统在启动时加载bonding模块,对外虚拟网络接口设备为 bond0
加入下列两行
alias bond0 bonding
options bond0 miimon=100 mode=1
说明:miimon是用来进行链路监测的。 比如:miimon=100,那么系统每100ms监测一次链路连接状态,如果有一条线路不通就转入另一条线路;mode的值表示工作模式,他共有0,1,2,3四种模式,常用的为0,1两种。
mode=0表示load balancing (round-robin)为负载均衡方式,两块网卡都工作。
mode=1表示fault-tolerance (active-backup)提供冗余功能,工作方式是主备的工作方式,也就是说默认情况下只有一块网卡工作,另一块做备份.
bonding只能提供链路监测,即从主机到交换机的链路是否接通。如果只是交换机对外的链路down掉了,而交换机本身并没有故障,那么bonding会认为链路没有问题而继续使用
4 # vi /etc/rc.d/rc.local
加入两行
ifenslave bond0 eth0 eth1
route add -net 172.31.3.254 netmask 255.255.255.0 bond0
route add -net 192.168.228.0 netmask 255.255.255.0 gw 192.168.228.153 dev eth0
#service network restart
到这时已经配置完毕重新启动机器.
重启会看见以下信息就表示配置成功了
…………….
Bringing up interface bond0 OK
Bringing up interface eth0 OK
Bringing up interface eth1 OK
…………….
下面我们讨论以下mode分别为0,1时的情况
mode=1工作在主备模式下,这时eth1作为备份网卡是no arp的
[root@redflag network-scripts]# ifconfig 验证网卡的配置信息
bond0 Link encap:Ethernet HWaddr 00:0E:7F:25:D9:8B
inet addr:172.31.0.13 Bcast:172.31.3.255 Mask:255.255.252.0
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:18495 errors:0 dropped:0 overruns:0 frame:0
TX packets:480 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1587253 (1.5 Mb) TX bytes:89642 (87.5 Kb)
eth0 Link encap:Ethernet HWaddr 00:0E:7F:25:D9:8B
inet addr:172.31.0.13 Bcast:172.31.3.255 Mask:255.255.252.0
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:9572 errors:0 dropped:0 overruns:0 frame:0
TX packets:480 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:833514 (813.9 Kb) TX bytes:89642 (87.5 Kb)
Interrupt:11
eth1 Link encap:Ethernet HWaddr 00:0E:7F:25:D9:8B
inet addr:172.31.0.13 Bcast:172.31.3.255 Mask:255.255.252.0
UP BROADCAST RUNNING NOARP SLAVE MULTICAST MTU:1500 Metric:1
RX packets:8923 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:753739 (736.0 Kb) TX bytes:0 (0.0 b)
Interrupt:15
那也就是说在主备模式下,当一个网络接口失效时(例如主交换机掉电等),不回出现网络中断,系统会按照cat /etc/rc.d/rc.local里指定网卡的顺序工作,机器仍能对外服务,起到了失效保护的功能.
在mode=0 负载均衡工作模式,他能提供两倍的带宽,下我们来看一下网卡的配置信息
[root@redflag root]# ifconfig
bond0 Link encap:Ethernet HWaddr 00:0E:7F:25:D9:8B
inet addr:172.31.0.13 Bcast:172.31.3.255 Mask:255.255.252.0
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:2817 errors:0 dropped:0 overruns:0 frame:0
TX packets:95 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:226957 (221.6 Kb) TX bytes:15266 (14.9 Kb)
eth0 Link encap:Ethernet HWaddr 00:0E:7F:25:D9:8B
inet addr:172.31.0.13 Bcast:172.31.3.255 Mask:255.255.252.0
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:1406 errors:0 dropped:0 overruns:0 frame:0
TX packets:48 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:113967 (111.2 Kb) TX bytes:7268 (7.0 Kb)
Interrupt:11
eth1 Link encap:Ethernet HWaddr 00:0E:7F:25:D9:8B
inet addr:172.31.0.13 Bcast:172.31.3.255 Mask:255.255.252.0
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:1411 errors:0 dropped:0 overruns:0 frame:0
TX packets:47 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:112990 (110.3 Kb) TX bytes:7998 (7.8 Kb)
Interrupt:15
在这种情况下出现一块网卡失效,仅仅会是服务器出口带宽下降,也不会影响网络使用.
通过查看bond0的工作状态查询能详细的掌握bonding的工作状态
[root@redflag bonding]# cat /proc/net/bonding/bond0
bonding.c:v2.4.1 (September 15, 2003)
Bonding Mode: load balancing (round-robin)
MII Status: up
MII Polling Interval (ms): 0
Up Delay (ms): 0
Down Delay (ms): 0
Multicast Mode: all slaves
Slave Interface: eth1
MII Status: up
Link Failure Count: 0
Permanent HW addr: 00:0e:7f:25:d9:8a
Slave Interface: eth0
MII Status: up
Link Failure Count: 0
Permanent HW addr: 00:0e:7f:25:d9:8b
Linux下通过网卡邦定技术既增加了服务器的可靠性,又增加了可用网络带宽,为用户提供不间断的关键服务。用以上方法均在redhat的多个版本测试成功,而且效果良好.心动不如行动,赶快一试吧!
最近碰到有问4块网卡如何配置2个bond网卡,测试了一下,配置方法略微有点不
同,主要是modprobe.conf里的配置:
1、ifcfg-bondX的配置和单个bond的配置没有区别;
2、修改modprobe.conf有2种修改方法:
a)当2个或者多个bond网卡的所有参数(即bonding模块的参数,如mode、miimon
等)都相同时,加载bonding模块时设置 max_bonds参数即可。如max_bonds=2时,
加载bonding驱动之后可以创建2个bond网卡bond0,bond1,修改后的
modprobe.conf和下面的情形类似:
…
alias bond0 bonding
alias bond1 bonding
options bond0 miimon=100 mode=1 max_bonds=2
…
b)当2个或者多个bond网卡的参数(即bonding模块的参数,如mode、miimon等)不
同时,需要在加载bonding模块时修改模块的名称(文档中的说法是linux的模块加
载系统要求系统加载的模块甚至相同模块的不同实例都需要有一个唯一的命名),
修改后的modprobe.conf和下面的情形类似:
…
alias bond0 bonding
options bond0 -o bond0 miimon=100 mode=0
alias bond1 bonding
options bond1 -o bond1 miimon=150 mode=1
…
(说明:使用 -o 选项在加载模块对模块进行重命名)
目前我只在DC5SP2上测试通过,其它版本并没有测试,内核的版本不同系统对
bonding模块的支持可能也有不同。
详细的文档参见内核文档/usr/src/linux-x.x.x-
xx.x/Documentation/networking/bonding.txt。
上午测试的时候修改modprobe.conf之后只是重启了network服务,所以当时以为第
二种方法也是生效了的。不过实际上,重启network 服务时,并没有卸载bonding
模块。当手动卸载bonding模块或者系统重启之后,网络服务启动的时候会报错,
说-o不是有效的选项。
重新看了一下文档,里面也提到了这个问题,所以modprobe.conf的修改还需要调
整一下,不再使用alias,options的格式,而使用下面的格式:
…
install bond0 /sbin/modprobe –ignore-install bonding -o bond0
miimon=100 mode=0
install bond1 /sbin/modprobe –ignore-install bonding -o bond1
miimon=100 mode=1
…
我也稍微修改了一下原来配置bond的脚本,基本可以用了。不过感觉我改完之后脚
本已经有点繁琐了,大家看一下。